

Wie KI Inhalte (Text, Video, Audio) innerhalb von Interfaces neu zusammensetzt — Unternehmen wie OpenAI und Google treiben 2026 die Integration multimodaler Systeme voran. Fachabteilungen implementieren Modelle, die nicht nur Text erzeugen, sondern gleichzeitig Bilder, Audio und Videosequenzen in Benutzeroberflächen verknüpfen, um Arbeitsabläufe zu beschleunigen und Zugänglichkeit zu verbessern.
Die Entwicklung betrifft vor allem Benutzeroberflächen und Interface-Design für Redaktionen, E‑Commerce und Bildung. Ausgangspunkt ist das Bedürfnis, Inhalte generieren und Textverarbeitung nahtlos mit Videobearbeitung und Audioproduktion zu verbinden, um Automatisierung und bessere Datenintegration zu erreichen.
Multimodale KI in Benutzeroberflächen: Text, Video und Audio zusammenführen
Multimodale Systeme funktionieren wie menschliche Wahrnehmung: Sie sehen, hören und lesen gleichzeitig. Vision-Language-Models ermöglichen es, ein Foto zu analysieren und daraus automatisch Bildunterschriften oder Produktbeschreibungen zu erzeugen.
Technische Grundlagen und Cross‑Modal‑Understanding
Das Kernelement ist Cross-Modal-Understanding: Die Modelle stellen Bezüge zwischen Bild, Ton und Text her und können so Aktionen in Interfaces auslösen. Beispiele in der Praxis reichen von automatischer Image-Captioning für Barrierefreiheit bis zu Document-Understanding, das OCR mit semantischer Analyse kombiniert.
Für Entwickler bedeutet das neue Anforderungen an Maschinelles Lernen und Architektur: Modelle brauchen multimodale Trainingsdaten, andockbare APIs und Mechanismen zur Konsistenzprüfung über Modalitäten hinweg. Diese technische Verschaltung verändert, wie Produkte Inhalte verarbeiten und an Nutzer ausliefern.
Das Ergebnis: Interfaces, die nicht nur darstellen, sondern verstandenes Material in Echtzeit adaptieren. Insight: Wer Interface-Design und Backend‑Datenintegration zusammendenkt, kann komplexe Medienaufgaben stark vereinfachen.
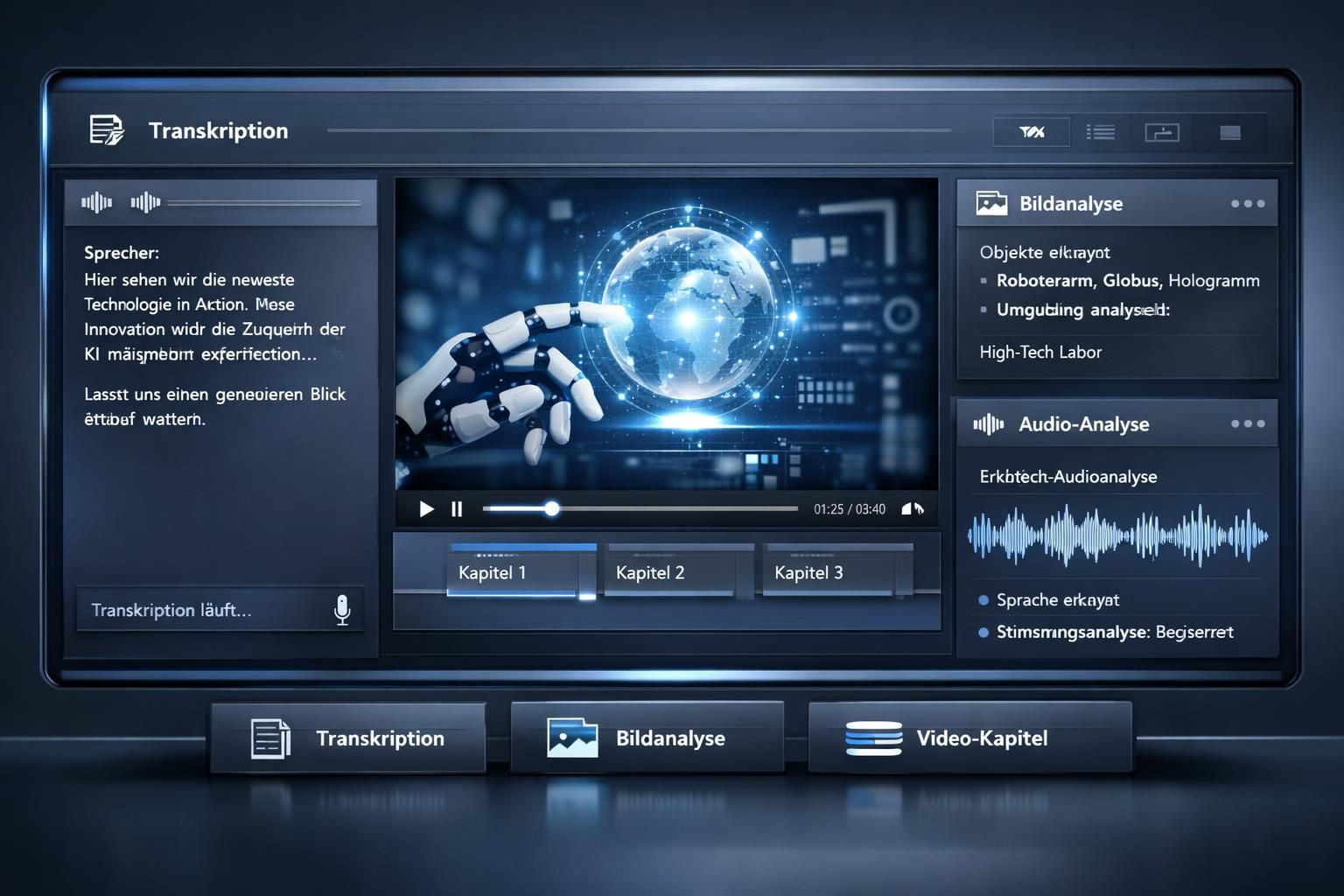
Praktische Anwendungen: Inhalte generieren, Videobearbeitung und Audioproduktion im Workflow
Multimodale KI verändert Produktionsketten. In Redaktionen entstehen Workflows, in denen ein Video automatisch transkribiert, in Kapitel strukturiert und als Social‑Media‑Teaser samt Bildgenerierung bereitgestellt wird. E‑Commerce nutzt Produkt-Image → Beschreibung → SEO-Text‑Pipelines, um Katalogpflege zu automatisieren.
Use Cases in Medien, Handel und Bildung
Tools wie Midjourney, DALL‑E und Stable Diffusion haben die Text‑to‑Image-Generation professionalisiert. Kombiniert mit Video‑Summarization und Audio‑Transcription entsteht eine Content‑Creation‑Pipeline: Rohmaterial → Analyse → Editor‑Vorschläge → finaler Ausspielpfad.
Für Bildungseinrichtungen bedeutet das personalisierte Lernpfade mit automatisch generierten visuellen Zusammenfassungen und Audioerklärungen. Für Produzenten heißt es: schnellere Iteration bei geringeren Produktionskosten durch Automatisierung. Insight: Multimodale Workflows sind besonders wirksam, wenn sie bestehende Toolchains integrieren und nicht ersetzen.
Herausforderungen: Datenintegration, Automatisierung und Urheberrecht
Trotz Potenzial sind Implementierung und Betrieb komplex. Performance und Rechenkosten steigen, wenn Video- und Audioverarbeitung hinzukommen. Trainingsdaten müssen multimodal und qualitativ hochwertig sein, was den Aufwand bei Maschinelles Lernen-Projekten erhöht.
Rechtliche, ethische und betriebliche Risiken
Multimodale Systeme verschärfen Fragen rund um Urheberrecht, Deepfakes und Stilnachahmung. Unternehmen müssen zusätzliche Prüfmechanismen einbauen, um Fälschungen zu erkennen und lizenzrechtliche Risiken zu minimieren. Qualitätssicherung fordert neue Metriken: nicht nur Textgenauigkeit, sondern Kohärenz zwischen Bild, Ton und Text.
Operationalisierung verlangt außerdem neue Rollen: Prompt‑Engineering für multimodale Aufgaben, Spezialisten für Datenintegration und Architekten für Echtzeit‑Automatisierung. Ohne klare Governance drohen Fehlausspielungen und Reputationsschäden. Insight: Governance, Monitoring und transparente Datenquellen sind Voraussetzung, damit Multimodalität sicher skaliert.






